


E’ ormai noto che una nuova BuzzWord sta affermandosi in internet e sta forse sostituendosi, o aggiungendosi, alla ormai vecchia “Cloud Computing”.
I BigData.
I due termini, oggetto del bombardamento mediatico internet, sono anche due termini molto strettamente legati tra di loro, come vogliamo dimostrare di seguito. Come vogliamo anche mostrare quanto il mondo BigData sia anch’esso profondamente legato al mondo OpenSource, vediamo ad esempio il legame tra il Cloud Computing e l’OpenSource, nella nostra vecchia nota.
Definizione
Iniziamo con qualche definizione di BigData, per cercare di arginare i soliti errori giornalistici sensazionalistici, o errori voluti a scopo di marketing, come siamo stati abbondantemente abituati relativamente il Cloud Computing. Esiste qualche definizione ufficiale?
Citiamo, WikiPedia, Gartner, IBM e la Villanova University di Tampa (Florida) e più in la anche il NIST:
Gartner – preso dal glossario
IBM – e suggerisco anche questa loro infografica delle 4V
Pertanto sembrano un pò tutti d’accordo nel definire i bigdata come “una raccolta di dati così grande e complessa da richiedere strumenti differenti da quelli tradizionali per essere analizzati e visualizzati”. Poi iniziano un pò di differenze:
Tutti d’accordo che “I dati sarebbero provenienti potenzialmente da fonti eterogenee”, e qui c’è chi sostiene che sono tutti “dati strutturati” e chi invece vi aggiunge anche “dati non strutturati”.
Veniamo alle dimensioni che questi dati devono avere per essere chiamati BigData, qui ovviamente c’è discordanza e wikipedia in inglese giustamente sostiene che la bigdata size è costantemente in movimento, non potrebbe d’altronde essere diversamente considerando i tantissimi studi che ogni anno analizzano la crescita dei dati prodotti a livello mondiale. Nel 2012 si parlava di un range da dozzine di terabyte a diversi petabyte, per ogni dataset, mentre ora si parla di zettabyte (miliardi di terabyte).
Nel merito citiamo questo articolo provocatorio di Marco Russo inviato a Luca De Biase e da questo pubblicato nel suo blog.
Sulle caratteristiche dei BigData tutti sono d’accordo sulle 3 V:
- volume: capacità di acquisire, memorizzare ed accedere a grandi volumi di dati;
- velocità: capacità di effettuare analisi dei dati in tempo reale o quasi;
- varietà: riferita alle varie tipologie di dati, provenienti da fonti diverse.
Ed alcuni parlano di una 4′ V:
- veridicità: ossia la qualità dei dati intesa come il valore informativo che si riesce ad estrarre
Ma cosa sta facendo il NIST relativamente la definizione di BigData? Si sa che il NIST si muove lentamente e macchinosamente, lo abbiamo imparato dai numerosi mesi o meglio anni in cui la definizione di Cloud Computing era permanentemente in bozza, ed iniziarono a lavorarci dal 2008.
Ebbene il NIST si inizia a muovere quando il governo USA decide di stanziare $200mil nella BigData Iniziative, parte cosi il BigData WorkShop del NIST ed un Working Group aperto a tutti, cosi come fu fatto per la definizione e tutti i documenti correlati al termine Cloud Computing
EcoSistema
Per mostrare la dimensione dell’ecosistema mondiale che ruota attorno a questo termine, osserviamo di seguito tre infografiche rispettivamente di Bloomberg, Forbes e Capgemini.


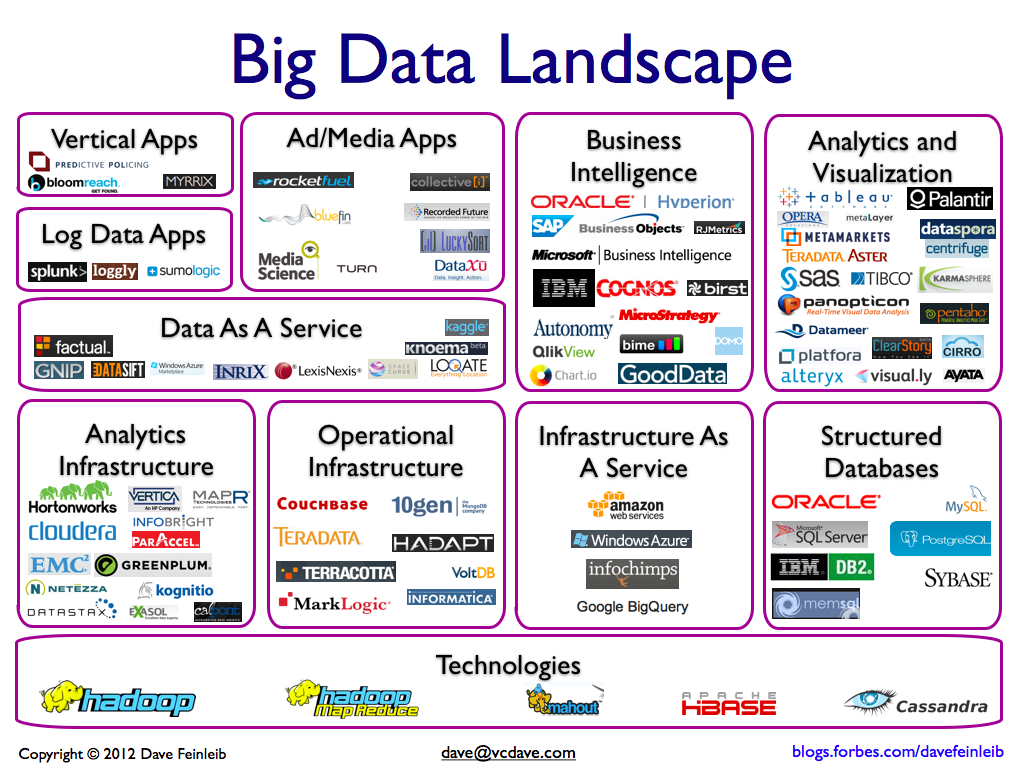

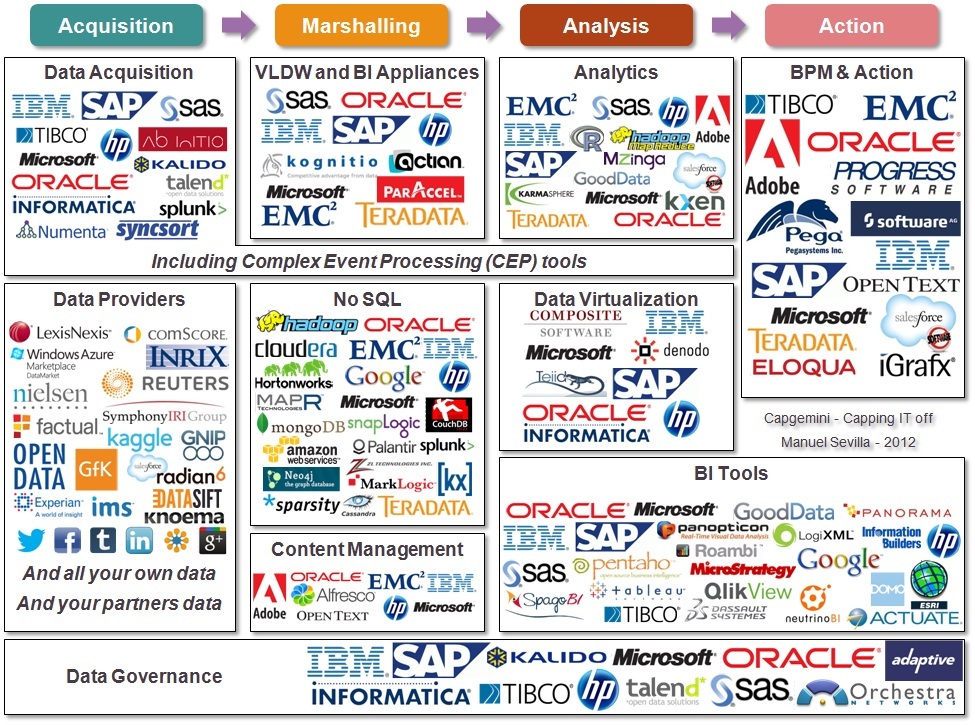
Già da queste tre infografiche si evidenzia come siano massicciamente usate le soluzioni OpenSource nell’ecosistema BigData, addirittura Forbes nelle tecnologie mette solo sw OpenSource.
Dimensione
Vediamo un pò che mercato e che crescita c’è attorno a questo ecosistema BigData
Secondo Gartner (dati 2012), Big Data Will Drive $28 Billion of IT Spending , Big Data Creates Big Jobs: 4.4 Million IT Jobs Globally to Support Big Data By 2015
Ed ora gustiamoci queste due infografiche, una di Asigra e una dell’IBM, che si mostra molto attiva nel mondo BigData:

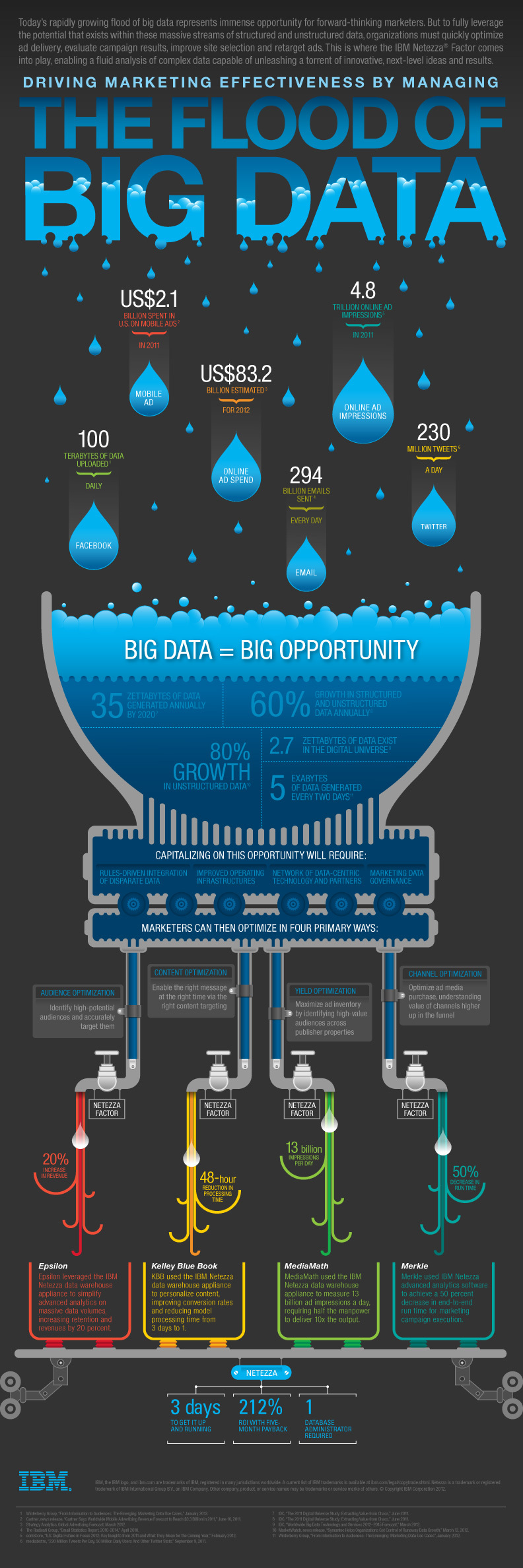


{kind=link}
Insomma il mercato dei BigData richiede fondamentalmente poche cose:
- Grandi sistemi di storage dei dati, ma veramente grandi
- Grande capacità di calcolo parallelo
- Personale qualificato (Data Analyst, Data Scientist) capace di “fiutare” dei risultati interessanti analizzando grosse quantità di dati apparentemente slegati tra loro.
- SW di acquisizione dei dati continua, SW di analisi dei dati e SW di raffigurazione visuale dei dati
Opportunità
I BigData, a mio giudizio, sono una grandissima opportunità per le grandi imprese di HW e SW IT (IBM,HP,EMC,Oracle,etc) in quanto risvegliano le necessità delle imprese verso l’acquisto di HW piuttosto che l’uso del Cloud Pubblico. Cresce anche l’esigenza di SW semplice, dedicato e personalizzato alle Data Analisi. Certo in molti casi si potrebbe mantenere e processare i dati presso i Cloud Provider, e questo è quello che già da diverso tempo consentono di fare i leader del mercato tipo AWS, con DynamoDB, RedShift, Elastic MapReduce, ma mantenere petabyte o zettabyte (se questi sono i valori a cui dobbiamo fare riferimento per poter parlare di Bigdata) in Cloud costa veramente tanto e credo possa addirittura convenire mantenersi una propria infrastruttura. Diverso è se abbiamo alcuni terabyte di dati su cui vogliamo fare DataAnalysis, e credo sia questo lo scenario più generale, dove i servizi di un Cloud pubblico tipo AWS diventano veramente concorrenziali.
Recentemente i Big dell’IT hanno fatto partite moltissime opportunità per imprese, startup e mondo della ricerca relativamente i BigData, per esempio EMC annuncia l’Hadoop Starter kit 2.0, oppure Microsoft che propone Hadoop nel cloud di Azure, oppure SAS si allea con SAP sulla piattaforma Hana, inoltre SAP HANA onDemand in AWS, o INTEL e AWS che offrono trial e gratuità, insomma c’è n’è per tutti i gusti, è una vera esplosione per l’economia IT.
Open Source e Cloud Computing
Sul BigData ed il Cloud Computing in pratica abbiamo già risposto, le possibilità sono tantissime, abbiamo citato il leader maximo (AWS) ed Azure, come offerte di Public Cloud, ma anche Google non manca di strumenti utili (BigQuery), d’altra parte basta ricordarci la famosa ed ormai vecchia BigTable di Google, che viene usata per il loro motore di ricerca.
Il Cloud Pubblico anche nel caso dei BigData può essere molto utile e molto democratico (sempre se non consideriamo le dimensioni dei dataset cosi come le definizioni vorrebbero). Pensate appunto alla semplicità di non dover gestire i sistemi di storage, i backup, i disaster recovery, di non dover gestire i SW di DataAnalysis (se usiamo qualche soluzione PaaS o SaaS), alla semplicità di poter mantenere poca potenza attiva durante i periodi di non analisi (pagando poco) e di poter istanziare potenza di calcolo solo durante le nostre query.
Veniamo ora al BigData e l’OpenSource; come abbiamo potuto finora rilevare un nome risuona forte in tutti gli scenari finora citati, HADOOP.
Hadoop è un framework software open-source (licenza Apache 2.0) per salvare e processare grandi quantità di dati in clusters di commodity hardware; nasce nel 2005 da Doug Cutting e Mike Cafarella e se non ricordo male nacque proprio come emulazione SW della BigTable di Google, per progetti di motori di ricerca concorrenti.
Da questo progetto ne sono nati tantissimi e sono nate anche tantissime soluzioni di storage distribuito. Hadoop ha ad esempio tantissimi progetti figlio, quali:
- HDFS, un file system distribuito.
- Cassandra, un database scalabile multi-master senza point of failure (usato da Facebook).
- HBase, un database distribuito per dati strutturati per gradissime tabelle (miliardi di righe e milioni di colonne).
- Hive, un data warehouse che consente in maniera semplice querying e gestione di grandi datasets residenti in storage distribuiti.
- Pig, una piattaforma per l’analisi di grandi insiemi di dati consistente di un linguaggio di alto livello. I programmi Pig hanno la caratteristica di poter essere eseguiti in parallelo, quindi consente la analisi di grandi quantità di dati in breve tempo.
- Mahout, un progetto per produrre implementazioni di algoritmi di machine-learning scalabili concentrati principalmente nelle aree di collaborative filtering, clustering e classificazione.
per citare i più noti del mondo Hadoop.
Ma l’opensource al servizio dei BigData non si ferma qui:
- Infinidb, è un database per il data warehousing. Abilitato per MySQL con una tecnologia column-oriented, è appositamente costruito per carichi di lavoro di analisi, interrogazione analitica, supporto transazionale e operazioni di bulk load. Abilitato anche per Hadoop.
- SciDB, è una piattaforma di gestione dati e analisi avanzate all-in-one. Altamente scalabile, per analisi complesse con un sistema di versioning dei dati, per esigenze commerciali e scientifiche. E’ una piattaforma software capace di girare su una griglia di hardware commodity o in Cloud.
- OpenTSDB, è Time Series Database che si appoggia a HBase+Hadoop, è un sistema distribuito di acquisizione ed analisi distribuita di grosse serie di dati temporali, tipo le misurazioni scientifiche o metereologiche.
- RRDTool, desidero citarlo anche se non andrebbe inserito in strumenti per BigData, perchè non nasce per lavorare grosse quantità di dati, ma ben si presta per le raffigurazioni grafiche, ha dimensioni finite delle proprie serie di dati, ma calcola continuamente le statistiche ad ogni nuovo inserimento di nuovi dati.
- MySQL per i BigData, MySQL il database per eccellenza del mondo Open, il più usato al mondo, non è da meno, anche se la attuale tendenza vede una forte spinta per il mondo NoSQL, ma MySQL ha da tantissimo tempo delle features per i bigdata, pensiamo solo alla possibilità di partitioning dei dati per velocizzarne le query, poi la scalabilità di MySQL è nota ai più.
- talend, ha una serie di prodotti di grandissimo livello che lascia scaricare, basando il proprio business su supporto,consulenza,training e certificazione. Qui potrai trovare recenti tutorial da consultare subito gratuitamente.
- Scipy, una serie di librerie Python-based per matematica, science, ed ingegneria.
- gnuplot, una potente CLI per svariati sistemi operativi per raffigurare i dati in potenti e bellissimi grafici
- R, è un ambiente software per il calcolo statistico e la grafica, legato a questo strumento troviamo anche dei pacchetti interessanti rOpenSci
- mongodb, è il più noto dei database NoSQL, altamente scalabile, e con feature di Map/Reduce, cioè con un modello di programmazione per l’elaborazione di grandi insiemi di dati in parallelo, con algoritmi distribuiti in clusters.
- couchdb, credo si possa definire un concorrente di mongodb.
- Neo4j, è un graph-database scalabile, robusto e completamente ACID.
- Presto è un motore di ricerca open source distribuito per l’esecuzione di query SQL interattive analitiche su fonti di dati di tutte le dimensioni che vanno da gigabyte a petabyte.
Per ora ci fermiamo qui ma continueremo ad aggiornare l’articolo.